Future and Implications
The Future of AI
Rodney Brooks AI Scorecard: a far less optimistic view of the future, from a guy who’s been active in the field since the 1980s.
Gary Marcus agrees, at least for self-driving cars.
Uber and Lyft can stop worrying about being disintermediated by machines; they will still need human drivers for quite some time.
and also Gary Marcus recommends:
For example, you should really check out Macarthur Award winner Yejin Choi’s recent TED talk She concludes that we still have a long way to go, saying for example that “So my position is that giving true … common sense to AI, is still moonshot”. I do wish this interview could have at least acknowledged that there is another side to the argument.)
Data and LLM Futures
AI will run out of training data in 2026 says Villalobos et al. (2022)
Our analysis indicates that the stock of high-quality language data will be exhausted soon; likely before 2026. By contrast, the stock of low-quality language data and image data will be exhausted only much later; between 2030 and 2050 (for low-quality language) and between 2030 and 2060 (for images).
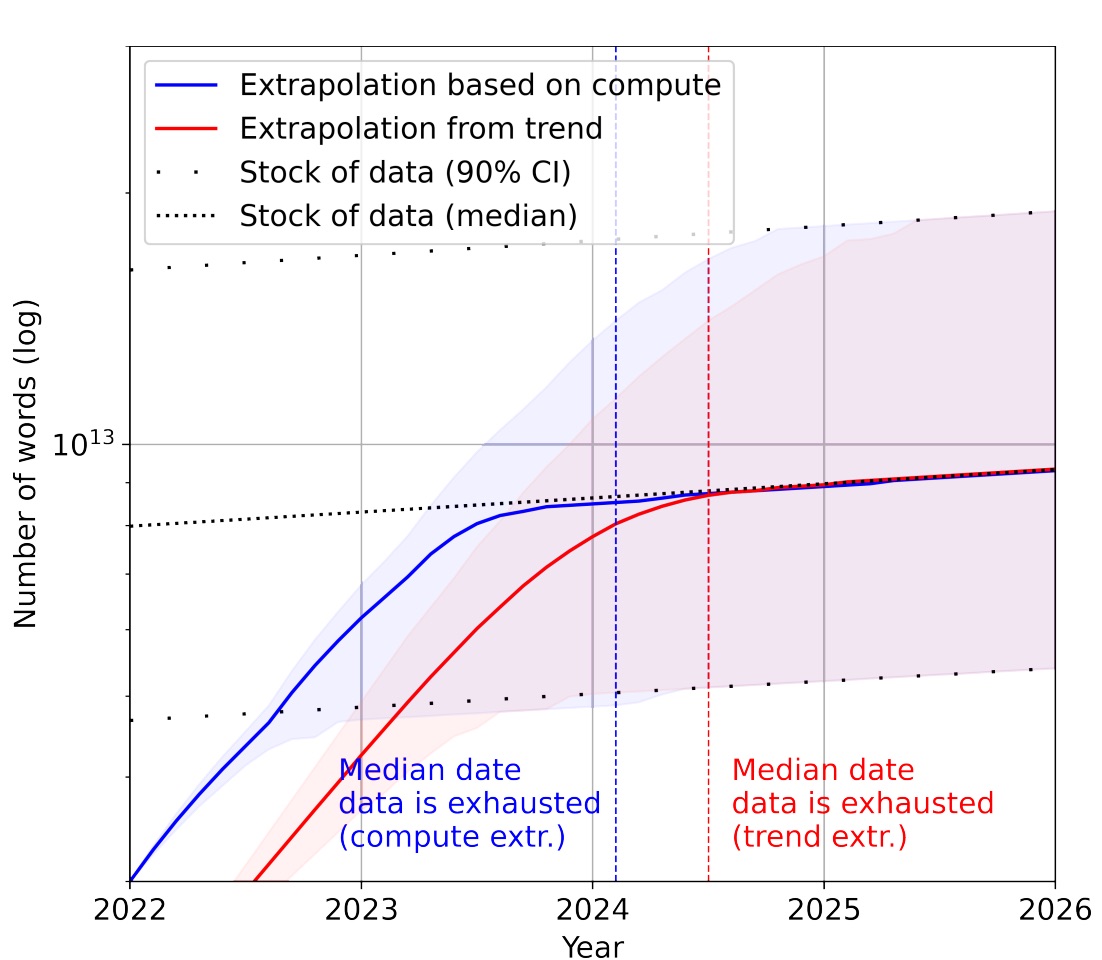
and “Model Collapse” will severely degrade the quality of these models over time, greatly increasing the value of human-collected data. Shumailov et al. (2023)
Sequoia Capital asks AI’s $200B Question “GPU capacity is getting overbuilt. Long-term, this is good. Short-term, things could get messy.”

Matt Rickard explains why data matters less than it used to:
A lot of focus on LLM improvement is on model and dataset size. There’s some early evidence that LLMs can be greatly influenced by the data quality they are trained with. WizardLM, TinyStories, and phi-1 are some examples. Likewise, RLHF datasets also matter.
On the other hand, ~100 data points is enough for significant improvement in fine-tuning for output format and custom style. LLM researchers at Databricks, Meta, Spark, and Audible did some empirical analysis on how much data is needed to fine-tune. This amount of data is easy to create or curate manually.
Model distillation is real and simple to do. You can use LLMs to generate synthetic data to train or fine-tune your own LLM, and some of the knowledge will transfer over. This is only an issue if you expose the raw LLM to a counterparty (not so much if used internally), but that means that any data that isn’t especially unique can be copied easily.
But the authors at Generating Conversation explain OpenAI is too cheap to beat. Some back-of-the-envelope calculations show that it costs their company 8-20x more to do a model themselves than to use the OpenAI API, thanks to economies of scale.
Jobs
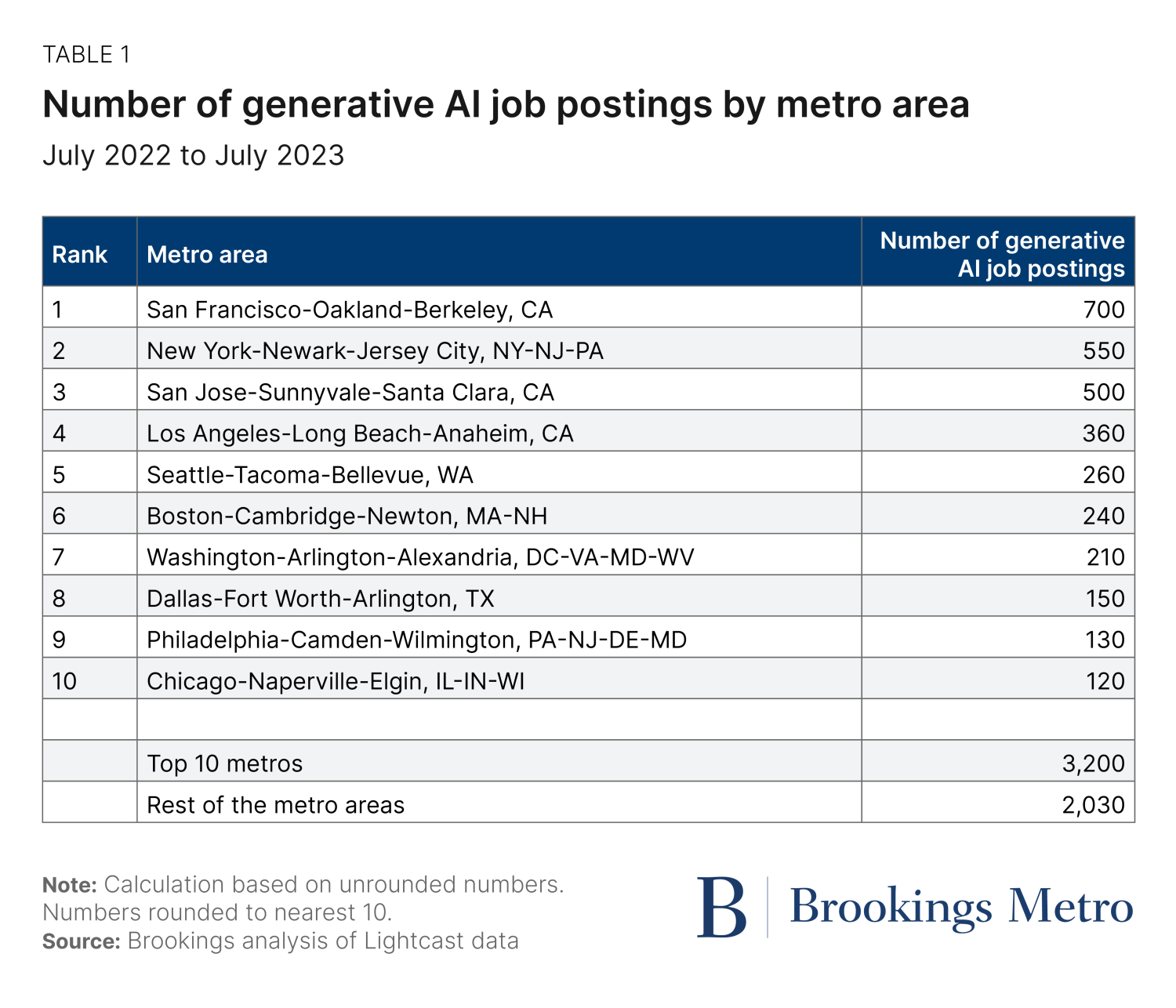
A Brookings Report says AI job postings happen in the same big tech hubs:
FT summarizes a Goldman Sachs report on AI displacing workers
Expert Forecasts
A October 2023 survey of attendees at AI conferences concludes that progress is happening faster than many expected, but that opinions are highly-fragmented.
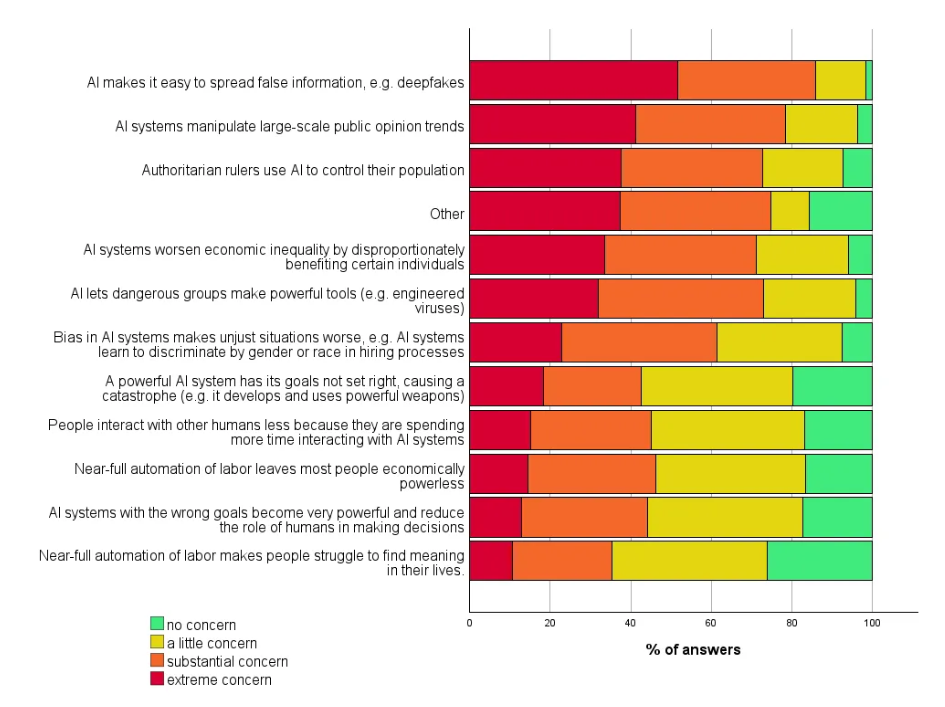
Scott Alexander summarizes the results of a large survey of AI Experts, one taken in 2016 and another in 2022. Although the first one seemed uncannily accurate on some of the predictions – e.g. likelihood AI could write a high school essay in the near future – a closer look at the survey wording reveals that the experts were mostly wrong.
Bounded-Regret is a site that makes calculated forecasts about the future of AI.
For example, the claim that by 2030, LLM speeds will be 5x the words/minute of humans:
benchmarking against the human thinking rate of 380 words per minute (Korba (2016), see also Appendix A). Using OpenAI’s chat completions API, we estimate that gpt-3.5-turbo can generate 1200 words per minute (wpm), while gpt-4 generates 370 wpm, as of early April 2023.
Benedict Evans thinks Unbundling AI is the next step. ChatGPT is too general, like a blank Excel page. And as with Excel, maybe a bunch of templates will try to guide users but ultimately each template just wants to be a specialized company. We await a true paradigm shift, as an iPad is to pen computing, we want LLMs that do something truly unique that can’t be done other ways.
Bill Gates thinks GPT technology may have plateaued and that it’s unlikely GPT-5 will be as significant an advance as GPT-4 was.
MIT Economist Daron Acemogulu argued that the the field could be in for a “great AI disappointment”, suggesting that “Rose-tinted predictions for artificial intelligence’s grand achievements will be swept aside by underwhelming performance and dangerous results.”
Alex Pan My AI Timelines Have Sped Up (Again) bets AGI will happen in 2028 (10% chance), 2035 (25%), 2045 (50%) and 2070 (90%):
Every day it gets harder to argue it’s impossible to brute force the step-functions between toy and product with just scale and the right dataset. I’ve been converted to the compute hype-train and think the fraction is like 80% compute 20% better ideas. Ideas are still important - things like chain-of-thought have been especially influential, and in that respect, leveraging LLMs better is still an ideas game.
Prediction Markets
LessWrong makes predictions

ChatGPT is pretty bad at making predictions, according to dynomight, who compared its predictions to those from the Manifold prediction market.

At a high level, this means that GPT-4 is over-confident. When it says something has only a 20% chance of happening, actually happens around 35-40% of the time. When it says something has an 80% chance of happening, it only happens around 60-75% of the time.
Limitations of Current AI
Paul Kedrosky & Eric Norlin of SK Ventures offer details for why AI Isn’t Good Enough
The trouble is—not to put too fine a point on it—current-generation AI is mostly crap. Sure, it is terrific at using its statistical models to come up with textual passages that read better than the average human’s writing, but that’s not a particularly high hurdle.
How do we know if something is so-so vs Zoso automation? One way is to ask a few test questions:
Does it just shift costs to consumers?
Are the productivity gains small compared to worker displacement?
Does it cause weird and unintended side effects?
Here are some examples of the preceding, in no particular order. AI-related automation of contract law is making it cheaper to produce contracts, sometimes with designed-in gotchas, thus causing even more litigation. Automation of software is mostly producing more crap and unmaintainable software, not rethinking and democratizing software production itself. Automation of call centers is coming fast, but it is like self-checkout in grocery stores, where people are implicitly being forced to support themselves by finding the right question to ask.
Chip Huyen presents a well-written list of Open challenges in LLM research:
- Reduce and measure hallucinations
- Optimize context length and context construction
- Incorporate other data modalities
- Make LLMs faster and cheaper
- Design a new model architecture
- Develop GPU alternatives
- Make agents usable
- Improve learning from human preference
- Improve the efficiency of the chat interface
- Build LLMs for non-English languages
Mark Riedl lists more of what’s missing from current AI if we want to get to AGI
The three missing capabilities are inexorably linked. Planning is a process of deciding which actions to perform to achieve a goal. Reinforcement learning — the current favorite path forward — requires exploration of the real world to learn how to plan, and/or the ability to imagine how the world will change when it tries different actions. A world model can predict how the world will change when an agent attempts to perform an action. But world models are best learned through exploration.
Dwarkesh Patel asks “Will Scaling Work” and concludes:
So my tentative probabilities are: 70%: scaling + algorithmic progress + hardware advances will get us to AGI by 2040. 30%: the skeptic is right - LLMs and anything even roughly in that vein is fucked.
His post is a lengthy point-counter-point discussion with technical details that confronts the question of whether LLMs can continue to scale after they’ve absorbed all the important data.
Zvi Mowshowitz: GPT-4 Plugs In: ’We continue to build everything related to AI in Python, almost as if we want to die, get our data stolen and generally not notice that the code is bugged and full of errors. Also there’s that other little issue that happened recently. Might want to proceed with caution…
Culture
Culture critic Ted Gioia says ChatGPT is the slickest con artist of all time
And Black Mirror creator, Charlie Brooker, who at first was terrified, quickly became bored:
“Then as it carries on you go, ‘Oh this is boring. I was frightened a sec ago, now I’m bored because this is so derivative.’
“It’s just emulating something. It’s Hoovered up every description of every Black Mirror episode, presumably from Wikipedia and other things that people have written, and it’s just sort of vomiting that back at me. It’s pretending to be something it isn’t capable of being.”
” AI is here to stay and can be a very powerful tool, Brooker told his audience.
“But I can’t quite see it replacing messy people,” he said of the AI chatbot and its limited capacity to generate imaginative storylines and ingenious plot twists.
AAAI 1989 paper describing an approach to AI intended to ” establish new computation-based representational media, media in which human intellect can come to express itself with different clarity and force.” The Mind at AI: Horseless Carriage to Clock
AI Doesn’t Have to be Perfect
A16Z Martin Casado and Sarah Wang The Economic Case for Generative AI and Foundation Models argue:
Many of the use cases for generative AI are not within domains that have a formal notion of correctness. In fact, the two most common use cases currently are creative generation of content (images, stories, etc.) and companionship (virtual friend, coworker, brainstorming partner, etc.). In these contexts, being correct simply means “appealing to or engaging the user.” Further, other popular use cases, like helping developers write software through code generation, tend to be iterative, wherein the user is effectively the human in the loop also providing the feedback to improve the answers generated. They can guide the model toward the answer they’re seeking, rather than requiring the company to shoulder a pool of humans to ensure immediate correctness.
Raising the bar on the purpose of writing
My initial testing of the new ChatGPT system from OpenAI has me impressed enough that I’m forced to rethink some of my assumptions about the importance and purpose of writing.
On the importance of writing, I refuse to yield. Forcing yourself to write is the best way to force yourself to think. If you can’t express yourself clearly, you can’t claim to understand.
But GPT and the LLM revolution have raised the bar on the type and quality of writing – and for that matter, much of white collar labor. Too much writing and professional work is mechanical, in the same way that natural language translation systems have shown translation work to be mechanical. Given a large enough corpus of example sentences, you can generate new sentences by merely shuffling words in grammatically correct ways.
What humans can do
So where does this leave us poor humans? You’ll need to focus on the things that don’t involve simple pattern-matching across zillions of documents. Instead, you’ll need to generate brand new ideas, with original insights that cannot be summarized from previous work.
Nassim Taleb distinguishes between verbalism and true meaning. Verbalism is about words that change their meaning depending on the context. We throw around terms like “liberal” or “populist”, labels that are useful terms for expression but not real thought. Even terms that have mathematical rigor can take on different meanings when used carelessly in everyday conversation: “correlation”, “regression”.

Mathematics doesn’t allow for verbalism. Everything must be very precise.
These precise terms are useful for thought. Verbalism is useful for expression.
Remember that GPT is verbalism to the max degree. Even when it appears to be using precise terms, and even when those precise terms map perfectly to Truth, you need to remember that it’s fundamentally not the same thing as thinking.
Mahowald et al. (2023) 1 argues:
Although LLMs are close to mastering formal competence, they still fail at functional competence tasks, which often require drawing on non-linguistic capacities. In short, LLMs are good models of language but incomplete models of human thought
References
Footnotes
(via Mike Calcagno: see Zotero↩︎